

پایش و پیشبینی پارامترهای کیفیت هوا در مناطق شهری وابسته به عوامل متعددی مانند توپوگرافی، اقلیم، جمعیت، شبکهی حمل و نقل میباشد که نحوه تعامل این عوامل مکانی به عنوان پدیده ای دینامیک، غیر خطی و دارای ابهام عنوان شده است.
در این راستا تکنیکهای هوش مصنوعی در مدل کردن پدیدههای غیر خطی و پیچیده دارای قابلیت فراوانی میباشند. شبکهی فازی- عصبی این قابلیت را در اختیار ما میگذارد که با استفاده از توانایی یادگیری شبکهی عصبی، دانش مورد نیاز در مورد پدیدهی مورد نظر را بدون نیاز به شخص خبره، در قالب قوانین مناسب بیان کنیم.
همچنین سیستم اطلاعات مکانی در قالب سیستمی توانمند، فرایند جمع آوری، ذخیره، پردازش و بصری سازی دادههای مکانی را تسهیل میبخشد. به علت اهمیت پیشبینی و مدلسازی مکانی پارامترهای کیفیت هوا، با بهرهگیری از مزایای شبکهی فازی-عصبی و GIS، دانش حاکم بر محیط را در قالب قوانین فازی، از دادهها استخراج نموده و با استفاده از این قوانین، آلودگی هوا پیشبینی و مدلسازی میشود.
برای این منظور از شبکهی فازی- عصبی و GIS در قالب دو مدل متفاوت استفاده میگردد. در مدل اول برای آموزش شبکه، دادههای آموزشی (شامل پارامترهای هواشناسی و غلظت مونوکسیدکربن) با استفاده از روش زمین آمار (کریجینگ) ایجاد و به کار میرود. برای هر ایستگاه ناحیهای در نظر گرفته و از دادههای موجود در آن ناحیه برای آموزش آن استفاده میشود. برای هر ناحیه قوانین فازی ممدانی و سوگنو استخراج و قوانین ایجاد شده به هر پیکسل آن ناحیه اعمال و میزان آلاینده تخمین زده میشود.
در مدل دوم هر ایستگاه به طور جداگانه با استفاده از دادههای خود آموزش داده شده و برای هر ایستگاه قوانین فازی ممدانی و سوگنو آن استخراج شده و با استفاده از این قوانین غلظت آلاینده تخمین زده میشود. به علت اینکه پیشبینی در نقاط ایستگاهها صورت میگیرد، در نهایت برای مدلسازی مکانی غلظت از روش کریجینگ استفاده میگردد. برای انجام تست عملی، از دادههای هواشناسی ایستگاههای واقع در سطح شهر استفاده میشود.
مدل اول با هدف به دست آوردن قوانین برای ناحیه توسعه داده شده که در این مدل گسستگی در نقشه ی غلظت آلاینده به دلیل کمبود ایستگاه های پایش و گستردگی ناحیه ها پایش هدف اصلی که اکتشاف دانش است، برای ناحیه مرتفع میشود.
در مدل دوم چون تعداد ایستگاه های پایش کم ، مدلی مناسبتر از نظر مدلسازی می باشد.
بحران های طبیعی همچون زله، طوفان و سیل قادر به تحمیل خسارات جبران ناپذیری به انسان و محیط زیست هستند. از این رو ارزیابی ریسک به منظور مدیریت مناسب و کاهش خسارات، حیاتی است. ارزیابی ریسک با فرایند برآورد احتمال وقوع یک رویداد و اهمیت یا شدت اثرات زیان آور آن مشخص می شود.
به منظور ارزیابی شدت آسیب پذیری از زله، پارامترهای مؤثر با استفاده از فرایند WASPAS وزن دهی میشوند. نقشه آسیب پذیری به روش همپوشانی شاخص و منطق فازی برای بلوک های آماری شهری تهیه و به صورت بصری در محیط سیستم اطلاعات مکانی ارایه میشوند.
نتایج حاکی از ارجحیت منطق فازی در تعیین آسیب پذیری مناطق است. مدل همپوشانی شاخص با تعداد مناسب کلاس های وزنی برای هر فاکتور می تواند نتایج مشابه با منطق فازی به بار آورد. علاوه بر آن مدل همپوشانی شاخص از مزایای سادگی، سرعت بیشتر در حل مسئله و انعطاف پذیری در ترکیب ورودی ها و رتبه بندی خروجی ها بهره می برد. روش مناسب برای تهیه نقشه آسیب پذیری به میزان فازی بودن پارامترها، انتخاب مناسب تابع عضویت و ادغام بهینه لایه های اطلاعاتی بستگی دارد.
روابط توپولوژیک میان عوارض مکانی فازی یکی از اطلاعات مهم و اساسی در سیستم های اطلاعات جغرافیایی (GIS) است. استخراج این نوع روابط، در کنار اطلاعات مکانی و توصیفی، می تواند در بسیاری از فرایندهای تصمیم گیری مورد استفاده قرار گیرد. برای مدل کردن این روابط مسائل و مشکلاتی وجود دارد؛ مانند متحرک بودن پدیده های مکانی، عدم قطعیت و ابهام در عوارض و ماهیت میان خود عوارض. این مشکلات باعث می شود استخراج این روابط پیچیدگی های زیادی داشته باشد.
روشی جدید برای مدل کردن این روابط و استخراج متغیرهای بیانی برای نواحی فازی قابل ارایه است. در این روش از محاسبه میزان شباهت میان ماتریس های اشتراکی کرسپ و فازی برای استخراج متغیرهای بیانی استفاده می شود.
این متغیرها دربردارنده نوع روابط توپولوژیک و کمیت سنج هایی هستند که قدرت روابط را نشان می دهند. با توجه به اینکه استخراج این متغیرها به عمل گرهای فازی وابستگی مستقیم دارند، مقایسه ای میان عمل گرهای مختلف فازی برای به دست آوردن جواب بهینه میتوان انجام داد. در پایان، سیستم استنتاج گر فازی بر اساس نوع روابط استخراج شده قابل طراحی است. این سیستم میزان پیغام هشدار را برای یک کاربرد خاص براساس میزان فرکانس فازی به کاربر اعلام می کند.
روش های تحلیل و ارزیابی مسائل درGIS به دو دسته داده مبنا و دانش مبنا تقسیم می شوند. در روش های دانش مبنا بکارگیری و تلفیق داده های ورودی به وسیله کارشناسان و متخصصان تعیین می شود و این مدل ها عمومیت بیشتری نسبت به مدل داده مبنا دارند.
سیستم استنتاج فازي(FIS )، سیستمی دانش مبنا میباشد که با استفاده از مجموعه ای از قوانین و بکارگیری متغیر های زبانی(مانند خوب، متوسط، ضعیف و.) به عنوان ورودی، آن ها را به روابط های ریاضی تبدیل می کند و قادر به استخراج نتیجه گیری صحیح از این داده ها می باشد.
كل سیستم استنتاج فازي، بر پايه قوانين "اگر، آنگاه " استوار است كه روابط مختلفی را میان متغیرهای ورودی و خروجی بر قرار می سازد. معیارهای موثر در پایداری کاربری های شهری نظیر امنیت در برابر زله، سازگاری کاربری ها و دسترسی به خدمات و.، را میتوان به صورت توابع فازی به عنوان متغیرهای ورودی وارد سیستم FIS کرده و با استفاده از قوانین موجود در پایگاه دانش، خروجی های مناسب که در واقع درجه تناسب هر منطقه نسبت به وضعیت ایده آل از نظر توسعه پایدار می باشد، بدست آورد. همچنین حساسیت نقشه های خروجی به معیارهای ورودی را نیز تحلیل کرد.
"در فرایند برنامهریزی استراتژیک ، زمان و عدم قطعیت، نقش مهمی ایفا میکنند.تغییرات غیرقابل پیشبینی در محیط، بسیاری از صنایع را زمینگیر ساخته و یا از صحنه رقابت حذف کرده است و پیشبینیها در مورد آینده را با شکست روبهرو ساخته است. سازمانها بهطور غیرقابل پیشبینی با تکنولوژیهای جدید، محصولات جدید و بازارهای جدید روبهرو میباشند و استراتژیهای تدوین شده، پاسخگوی نیاز آنها در چنین محیط پویا و متغیری نیست. این فشارها در آینده افزایش نیز خواهد یافت، زیرا که تغییرات تکنولوژیکی، اقتصادی و اجتماعی همچنان رو به گسترش است. بدیهی است که آینده قابل پیشبینی نیست. اما نکته قابل توجه این است که سازمانها میتوانند خود را برای مقابله با آن آماده کنند و این آمادگی سبب ایجاد مزیت رقابتی برای آنها میشود. هر چه عدم قطعیتها تشدید شود، مزیت رقابتی سازمانهایی که استراتژیهای پایدار و مقاوم را در برابر تغییرات تدوین کردهاند، نیز افزایش مییابد. هدف این مقاله معرفی روشی است که به سازمانها قابلیت تدوین استراتژیهای استوار در شرایط عدم قطعیت را میبخشد و آنها را در جهت مصون کردن استراتژیهای خود در برابر تغییرات محیطی هدایت میکند. روش معرفی شده در این مقاله، از این جهت که روش عمومی تدوین استراتژی را با دو ابزار مقابله با عدم قطعیت، یعنی برنامهریزی سناریو و سیستم استنتاج فازی ترکیب میکند، از تازگی و نوآوری برخوردار ساخته است. این روش با استفاده از عوامل غیرقطعی در محیط، اقدام به طراحی سناریوهای محتمل پیش روی سازمان کرده و با استفاده از اطلاعات فازی بیان شده بهوسیله خبرگان در سیستم استنتاج فازی اقدام به انتخاب استوارترین استراتژی سازمان در مواجهه با سناریوهای طراحی شده میپردازد. این روش به مدیران و برنامهریزان استراتژیک سازمانها، کمک میکند تا بتوانند با ارزیابی محیط آینده خویش، به بینش درستی در تدوین استراتژیهای سازمان دست یابند و مزیت رقابتی سازمان را در محیط آشفته و متغیر آینده حفظ کنند. این روش به مدیران و برنامهریزان استراتژیک سازمانها، کمک میکند تا بتوانند با ارزیابی محیط آینده خویش به بینش درستی در تدوین استراتژیهای سازمان دست پیدا کنند و مزیت رقابتی سازمان را در محیط آشفته و متغیر آینده حفظ کنند."
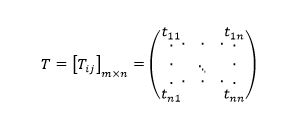
یک دستاورد مهم و با ارزش آمارگیری مبدا-مقصد، که با صرف و قت و هزینه بسیار، پس از جمعآوری اطلاعات سفر و تحلیل آنها به دست میآید، ارائهی ماتریس یا ماتریسهای مبدا-مقصد است.
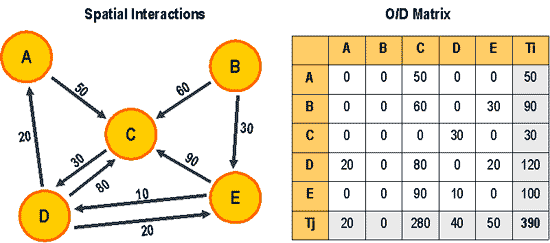
این ماتریس معمولا مربعی و ابعاد آن به اندازهی تعداد نواحی منطقهی مورد مطالعه میباشد و نشان می دهد هر ناحیه مانند i به هر ناحیه مانند j چه تعداد سفر صورت میگیرد.
میتوان ماتریس های مبدا-مقصد جزیی نیز با تحلیل آمار سفرها ارائه داد؛ مثلا " ماتریس مبدا- مقصد سفرهای اوج صبح با وسیله نقلیه شخصی".
با توجه به تعداد زیاد نواحی در مطالعات عملی، این ماتریس دارای ابعاد بزرگی خواهد بود. در صورت در اختیار داشتن ماتریسهای مبدا- مقصد خوب و نزدیک به واقعیت، علاوه بر توصیف وضع موجود، میتوان مدلهای واقع بینانهای برای تولید و جذب سفر و انتخاب وسیله با آن ساخت و سالها از آن برای پیشبینی ترافیک یک شهر استفاده نمود.
چون تعداد سفر ها اصولا با گذشت زمان افزایش می یابد لازم است پس از هر چند سال این ماتریس به هنگام update)) شود.
در ماتریس مبدا- مقصد، جمع درایههای هر سطر مانند i، تولید سفر i را نشان میدهد:
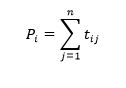
و جمع درایههای هر ستون مانند j نیز، جذب سفر ناحیه ی j را نشان میدهد:
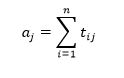
از آنجا که هر سفر دارای یک مبدا و یک مقصد است و سفری گم نمیشود داریم:

قابل توجه دانشجویان (تمامی رشته ها و گرایشها) :
وبلاگ (سمنان تز . بلاگ.آی آر SEMNANTEZ.BLOG) با بروزترین موضوعات تحقیقاتی و پژوهشی در قالب پروپوزال ، پایان نامه، مقاله و. آماده ارایه خدمات به شما عزیزان میباشد. آدرس وبلاگ در عنوان این مطلب قرار داده شده است.
نکته قابل ذکر اینکه علاوه بر تهیه فایل های پژوهشی خود از این وبلاگ، میتوانید پروپوزال، پایان نامهف مقاله خودرا نیز با هماهنگی مدیر وبلاگ، بصورت رایگان و یا فروش، در اختیار دیگران قرار دهید.
سمنان تز . بلاگ.آی آر
SEMNANTEZ.BLOG
سپاسگذارم.
در این راستا این موسسه میتواند با بکارگیری الگوریتم فراابتکاری مناسب، هر محقق، دانشجو ویا سازمان را در تولید جوابی منطقی در مدت زمان معقول یاری میرساند.
بهینگی: وقتی چندین جواب برای یک مسئله موجود است، الگوریتم هیوریستیک میتواند بهترینِ جوابها، از میان این تعداد را پیدا کند.
کامل بودن: هنگامی که چندین جواب برای مسئله موجود است، الگوریتم فراابتکاری میتواند اکثر آنها را پیدا کند.
دقت: هیوریستیک مربوطه میتواند جوابی با دقت بالا و خطای کم پیدا کند.
مدت زمان اجرا: زمان حل مسائل به کمک الگوریتمهای فراابتکاری بسیار کمتر از روشهای دستی است.
به ادامه مطلب مراجعه کنید
الگوریتم زنبور هر نقطه را در فضای پارامتری_ متشکل از پاسخ های ممکن_به عنوان منبع غذا تحت بررسی قرار می دهد."زنبور های دیده بان"_ کارگزاران شبیه سازی شده _به صورت کتره ای (Random) فضای پاسخ ها را ساده می کنند و به وسیله ی تابع شایستگی کیفیت موقعیت های بازدید شده را گزار ش می دهند. جواب های ساده شده رتبه بندی می شوند، و دیگر "زنبورها" نیروهای تازه ای هستند که فضای پاسخ ها را در پیرامون خود برای یافتن بالا ترین رتبه محل ها جستجو می کنند(که "گار" نامیده می شود) الگوریتم به صورت گزینشی دیگر گار ها را برای یافتن نقطه ی بیشینه ی تابع شایستگی جستجو می کند.
برای انجام طرح و تحقیق و پایان نامه بااستفاده از این مدل در محیط GIS با شماره همراه و یا ایمیل ذکر شده در این وبلاگ تماس بگیرید.

یک الگوریتم مبتنی بر ممتیک متاهیوریستیک است. این الگوریتم در سالهای اخیر توسط Eusuff و Lansey ایجاد شد. الگوریتم SFLA از نحوهی جستجوی غذای گروه های قورباغه سرچشمه میگیرد. این الگوریتم برای جستجوی محلی میان زیرگروههای قورباغه از روش نمو ممتیک استفاده میکند. SFLA از استراتژیِ ترکیب استفاده میکند و امکان مبادله پیام در جستجوی محلی را فراهم میسازد. این الگوریتم مزایای الگوریتم نمو ممتیک و بهینه سازیِ گروه ذرات (PSO) را ترکیب میکند. در SFLA نه تنها در جستجوی محلی بلکه در جستجوی سراسری نیز پیامها مبادله میشوند. بدین ترتیب جستجوی محلی و سراسری به خوبی در این الگوریتم ترکیب میشوند. جستجوی محلی امکان انتقال مم را میان افراد ممکن میسازد و استراتژیِ ترکیب امکان انتقال مم را میان کل جمعیت ممکن میسازد. مانند الگوریتم ژنتیک (GA) و بهینه سازی گروه ذرات (PSO) الگوریتم جهش ترکیبیِ قورباغه یک الگوریتم بهینه سازیِ مبتنی بر کولونی است. SFLA قابلیت بالایی برای جستجوی سراسری دارد و پیاده سازیِ آن آسان است. الگوریتم SFLA میتواند بسیاری از مسائل غیرخطی، غیرقابلتشخیص و چندحالته را حل کند.
الگوریتم SFLA ترکیب روش قطعی و روش تصادفی است. روش قطعی به الگوریتم امکان میدهد تا پیامها را به صورت کارایی مبادله کند. روش تصادفی انعطافپذیری و مقاومت الگوریتم را تضمین میکند. الگوریتم با انتخاب تصادفی گروه های قورباغه شروع میشود. گروههای قورباغه به چندین زیرگروه تقسیم میشوند. هر یک از این زیرگروهها میتوانند جستجوی محلی را به صورت مستقل و با روش متفاوتی انجام دهند. قورباغههای موجود در یک زیرگروه میتوانند بر روی سایر قورباغه های موجود در همان زیرگروه اثر بگذارند. بدین تریب قورباغه های موجود در یک زیرگروه تکامل مییابند. تکامل ممتیک کیفیت ممتیکِ قورباغه های منفرد را بهبود و قابلیت دستیابی به هدف را افزایش میدهد. برای رسیدن به یک هدف خوب میتوان وزنِ قورباغه های خوب را افزایش و وزن قورباغه های بد را کاهش داد. بعد از تکامل برخی از ممتیکها، زیرگروهها با هم ترکیب میشوند. بواسطهی ترکیب ممتیکها در حوزهی سراسری بهینه میشوند و بوسیله مکانیزم ترکیب زیرگروههای قورباغه جدیدی ایجاد میشود. ترکیب، کیفیتِ ممتیکهایی که تحت تاثیرِ زیرگروههای مختلف قرار میگیرند را افزایش میدهد. جستجوی محلی و جستجوی سراسری تا برآورده شدن شرط همگرایی ترکیب میشوند. توازن بین مبادله پیام سراسری و جستجوی محلی به الگوریتم امکان میدهد تا به راحتی از مینیمم محلی پرش کند و تا دستیابی به بهینه سازی توسعه یابد. یکی از خصیصه های الگوریتم SFLA همگرایی سریع آن است.
برای انجام طرح و تحقیق و پایان نامه بااستفاده از این مدل در محیط GIS با شماره همراه و یا ایمیل ذکر شده در این وبلاگ تماس بگیرید.



درباره این سایت